Programmiertes Entwerfen 2
Mental Health in Tech

Mein ausgewählter Datensatz stammt aus einer Umfrage aus dem Jahr 2014, die die Einstellung zur psychischen Gesundheit und die Häufigkeit psychischer Gesundheitsstörungen am Arbeitsplatz in der IT-Industrie misst.
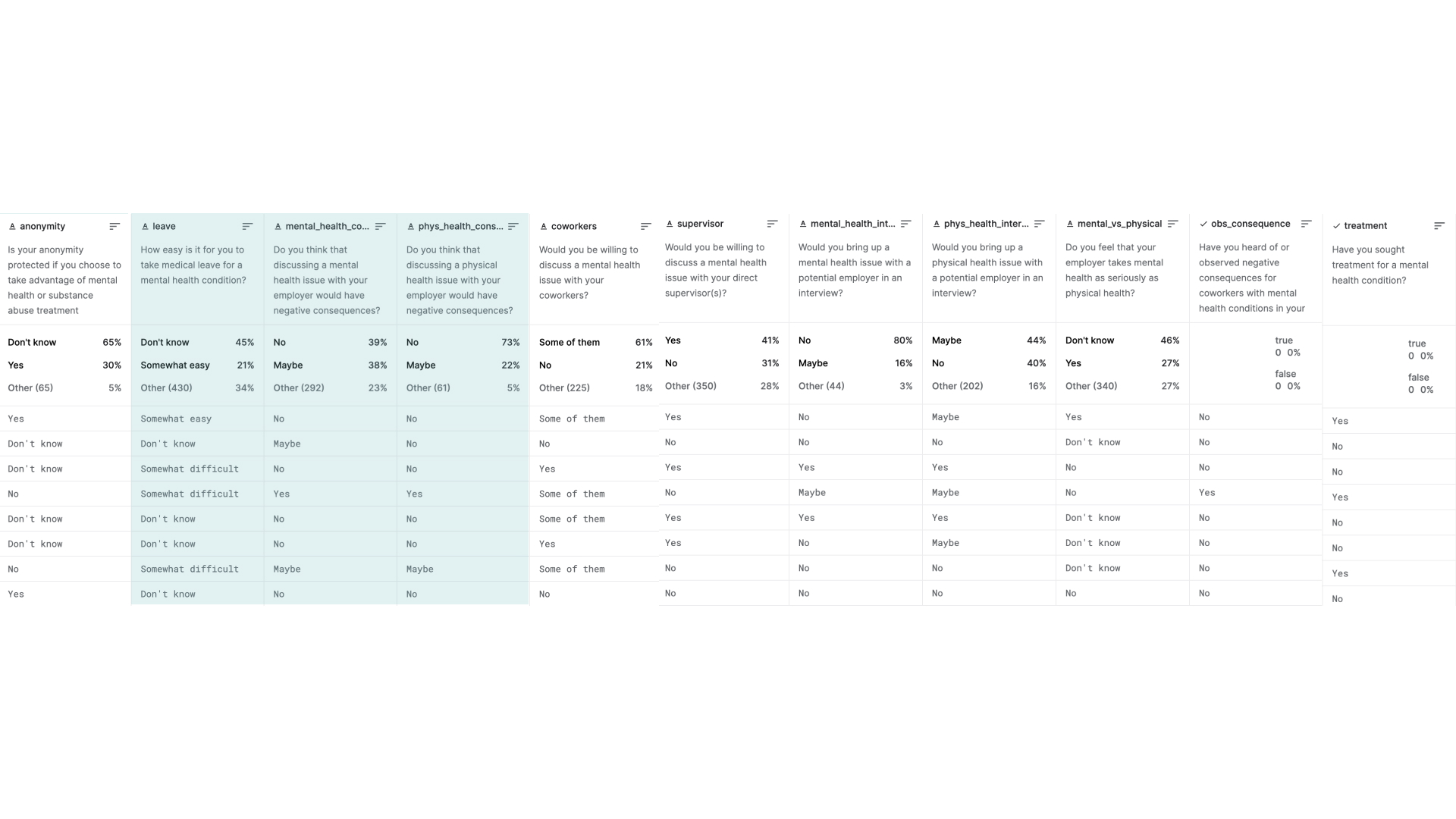
Der Datensatz beinhaltet 27 Dimensionen bzw. Fragen, die 1259 Menschen beantwortet haben. Und schon da ist mein erstes Problem aufgetaucht, nämlich ist das ein ziemlich untypischer Datensatz dadurch, dass es wenige numerische Daten enthält und stattdessen aus umfangreichen Fragen mit verschiedenen Antworten besteht.
Meine Aufgabe war, interessante Fragen zu finden, die aussagekräftig sind und miteinander in Korrelation gebracht werden können und in einem Zusammenhang ein klares Bild erzeugen. So habe ich mich erstmal von 27 auf 8 Dimensionen beschränkt.
Da nur 1259 Menschen befragt wurden, wurde mir schnell klar, dass ich alle 1259 darstellen kann, obwohl meine erste Vermutung war, dass ich sie in numerische Werte übersetzen müsste. Da ich alle Befragten visuell darstellen möchte, habe ich mich dafür entschieden, auch das Alter und das Geschlecht mit einzubringen, um einerseits die Visualisierung interessanter gestalten zu können und andererseits sind das wichtige Faktoren, die einige Antworten beeinflussen könnten.
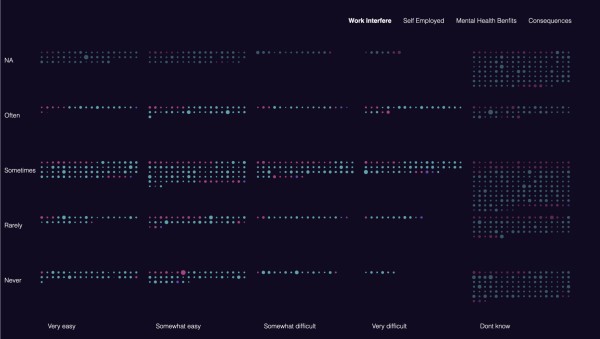
“ Wenn Sie unter einer psychischen Erkrankung leiden, haben Sie das Gefühl, dass dies Ihre Arbeit beeinträchtigt?” - war eine der Fragen, die ich am relevantesten abgesehen von der Thematik des Datensatzes fand. Darauf gab es fünf verschiedene Antworten: nie, selten, manchmal, oft und nicht angegeben . Danach habe ich mich auf die Suche nach der Frage, die man mit der ersten sinnvoll vergleichen könnte, gemacht. “Wie einfach ist es für Sie, sich wegen einer psychischen Erkrankung krankschreiben zu lassen?” - war eine der Fragen, die aus meiner Sicht im Zusammenhang mit der oben genannten gestellt werden könnte. Die Antworten wurden so angegeben: sehr leicht, etwas leicht, etwas schwierig, sehr schwierig und weiß nicht.
Danach suchte ich nach weiteren Indikatoren, die die Antworten auf die zwei Fragen stark beeinflussen könnten.
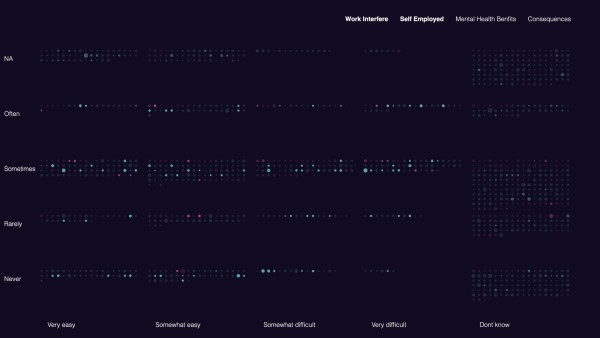
Ob die Menschen selbständig sind und ob Ihr Arbeitgeber Leistungen zur psychischen Gesundheit anbietet, könnte eine große Rolle bei der Häufigkeit der Interferenz der psychischen Gesundheit mit dem Arbeitsalltag spielen.
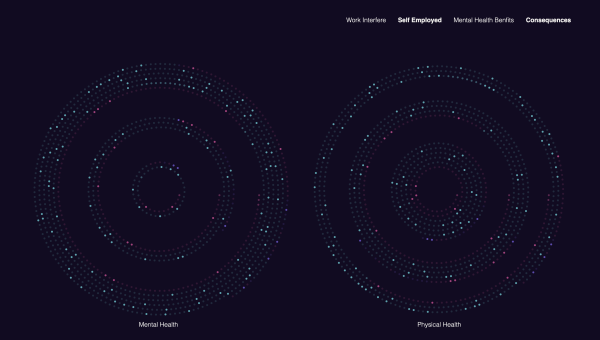
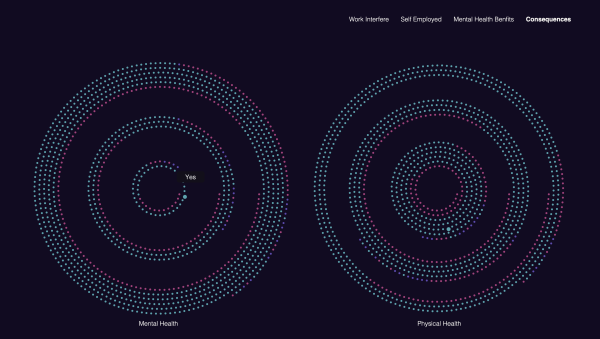
Die Umfrage bzw. der Datensatz enthält mehrere Fragen, die die psychische Gesundheit mit physischen vergleichen, die einen relativ spannenden Vergleich bilden könnten, weshalb ich mich für die nächsten zwei Fragen entschieden habe. Die so lauten: “Denken Sie, dass es negative Folgen hätte, wenn Sie mit Ihrem Arbeitgeber über ein psychisches Problem sprechen?” und “Denken Sie, dass es negative Folgen hätte, wenn Sie mit Ihrem Arbeitgeber über ein physisches Gesundheitsproblem sprechen?”. Auf beide Fragen wurde entweder ja, nein oder vielleicht geantwortet.
Erste Ansätze
Da ich mit Skizzen nicht so weit gekommen bin, abgesehen davon, dass ich keine Vorstellung hatte wie sich die Daten tatsächlich verteilen werden, habe ich mich dafür entschieden die erste Frage bzw. die Antworten auf die erste Frage auf die y-Achse zu legen und die zweite auf die x-Achse, was gleichzeitig die einzelnen Menschen innerhalb der Gitterstruktur positioniert. Somit kann man für jeden einzelnen Menschen sehen, welche Antwort er/sie auf die beiden Fragen gegeben hat.
Erste Varianten

Nachdem ich meine Daten zum ersten Mal auf dem Bildschirm gesehen habe, wurde mir klar, dass sie ein bisschen Abstand benötigen bzw. sollte man die Spalten und Zeilen voneinander trennen, was ich erstmal dadurch gelöst habe, dass ich über die einzelnen Fragen hovern kann, was dazu führt, dass die restlichen ausgeblendet werden. Dies war immer noch nicht die beste Lösung, da es optisch immer noch zu nah aneinander war. Da die Größe der Punkte durch das Alter bestimmt wurde, haben sie sich erstmal unterschiedlich positioniert bzw. die Punkte wurden nicht zentriert nebeneinander angeordnet. Das Ganze sah zu kastenförmig aus, und der Grund dahinter waren die sichtbaren x- und y-Achsen, die tatsächlich keinen Zweck erfüllen, und somit habe ich sie unsichtbar gemacht.
Ob die Menschen selbständig sind und ob ihr Arbeitgeber Leistungen zur psychischen Gesundheit anbietet, habe ich durch unterschiedliche Deckkraft der Punkte dargestellt. Nachdem man auf den “Self-Employed” span Button klickt, werden die Menschen, die nicht selbstständig sind, transparenter und die Selbstständigen bleiben mit einer hohen Deckkraft eingefärbt. Dasselbe geschieht mit den “Mental Health Benefits”, falls die Antwort auf die Frage “ja” war bleibt die 100%ige Deckkraft, haben die Menschen mit “Don`t know” beantwortet, werden die transparenter und die mit “Nein” als Antwort noch transparenter.

“Denken Sie, dass es negative Folgen hätte, wenn Sie mit Ihrem Arbeitgeber über ein psychisches Problem sprechen?”
“Denken Sie, dass es negative Folgen hätte, wenn Sie mit Ihrem Arbeitgeber über ein physisches Gesundheitsproblem sprechen?”- Die Fragen, die ich auf dem zweiten Screen als zwei Kreise nebeneinander dargestellt habe, die jeweils aus 3 Umfängen bestehen, die die drei unterschiedlichen Antworten präsentieren. Die meist gegebene Antworten habe ich als äußere Kreisumfänge dargestellt, wegen dem benötigten Platz.
Die ersten Kreisvarianten hatten zu große Abstände und wegen ihrer Positionierung der Punkte auch zu kleine Punkte, die kaum sichtbar sind.
Durch das Rumprobieren entstand die nächste Variante, die auch nicht optimal war.

Klar war, dass die Menschen, die dieselbe Antwort gegeben haben, nicht alle in einer Reihe positioniert werden können, falls man sie größer darstellen möchte. So sind sie je nach Anzahl der Menschen, die eine bestimmte Antwort gegeben haben, in 2 bis 7 Reihen innerhalb eines Kreisumfanges positioniert.