Programmiertes Entwerfen 2 (IG)
Car Accidents In Brazil
Diese Datenvisualisierung basiert auf den Informationen zu den Autounfällen in Brasilien aus den Jahren 2017-2023.
Der Datensatz
Der Datensatz stammt von der Plattform Kaggle und umfasst 27 Spalten sowie 463.152 Zeilen. Es handelt sich um einen sehr großen Datensatz, der als JSON-Download 224,3 MB groß ist. Aufgrund der immensen Anzahl an Daten war es nicht möglich, die JSON-Datei korrekt zu formatieren. Ich habe den Datensatz mithilfe eines Kaggle-Notebooks und Python auf die Anzahl der Spalten gekürzt, die die für die Programmierung benötigten Informationen enthalten, und anschließend als JavaScript-Datei exportiert. So war es mir möglich, den Datensatz problemlos einzubetten und zu verwenden.
Konzeptentscheidungen
Um zu entscheiden, welche Spalten aus dem Datensatz ich verwenden möchte, habe ich viele Scribbles angefertigt. Dadurch konnte ich mir einen ersten Überblick verschaffen und die interessantesten Informationen herausfinden. Besonders wichtig war mir die Gegenüberstellung verschiedener Daten, da ich mit meiner Visualisierung mögliche Zusammenhänge aufzeigen und Raum für Spekulationen schaffen wollte.
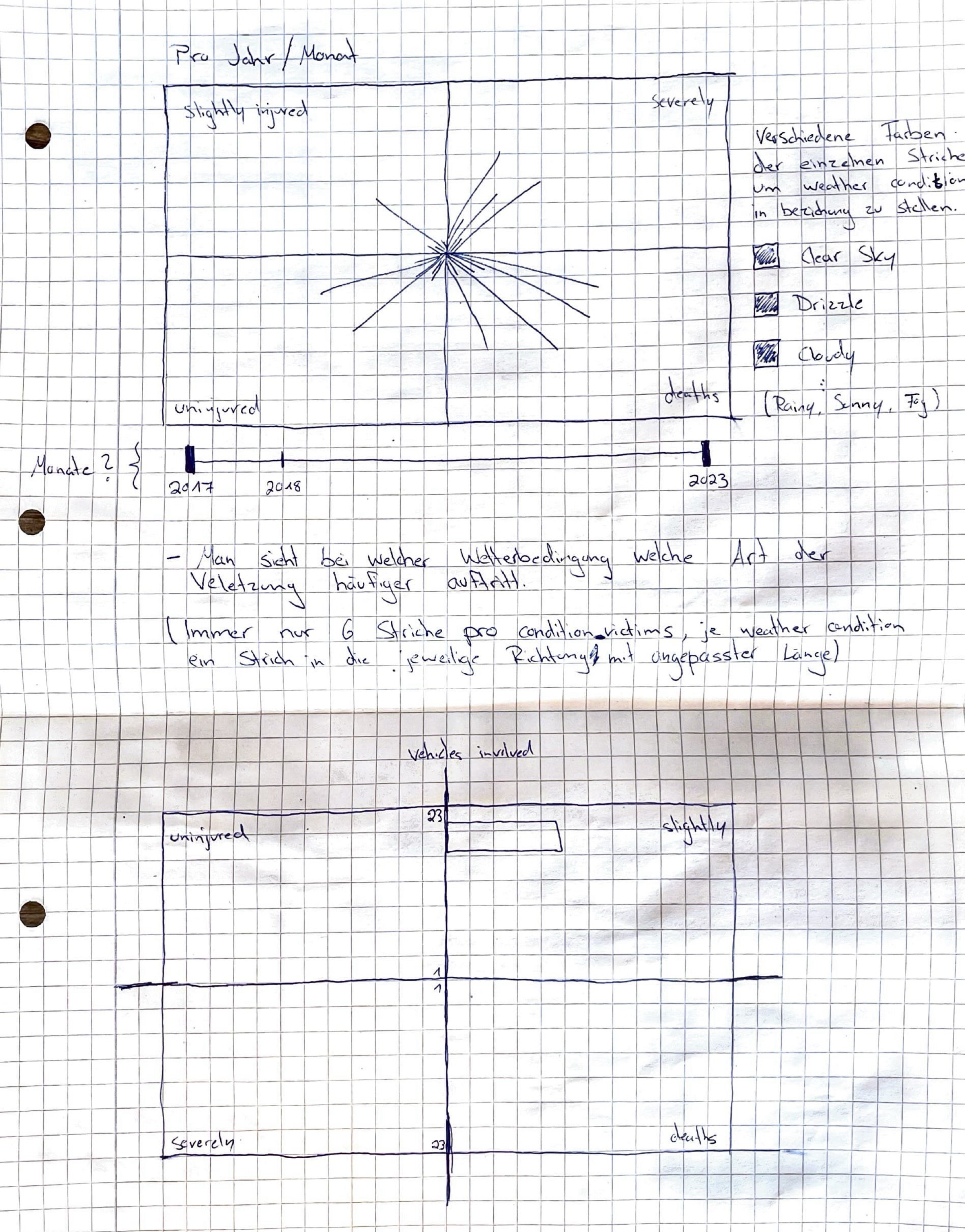
Visualisierung in Figma
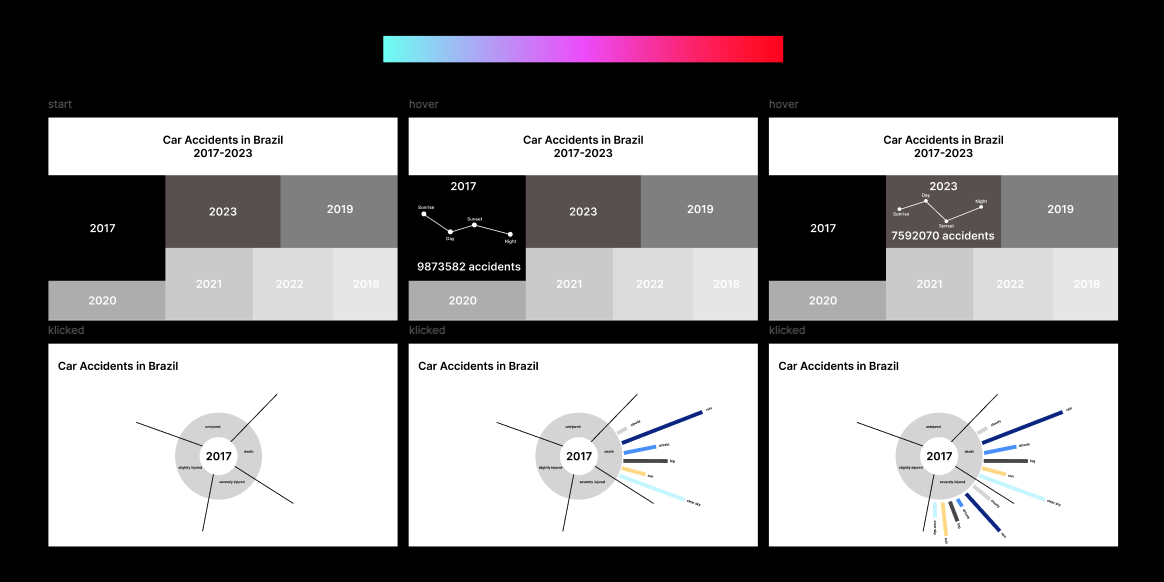
Um mir meinen Entwurf besser vorstellen zu können, habe ich ihn in Figma umgesetzt. So konnte ich die Hoverfunktionen einbauen und herumprobieren. In diesem Schritt fing ich an, mir Gedanken über die Farbe zu machen und entschloss, mit einem Farbverlauf zu arbeiten, der die Information über die Tödlichkeit des Jahres darstellt.
Finaler Entwurf
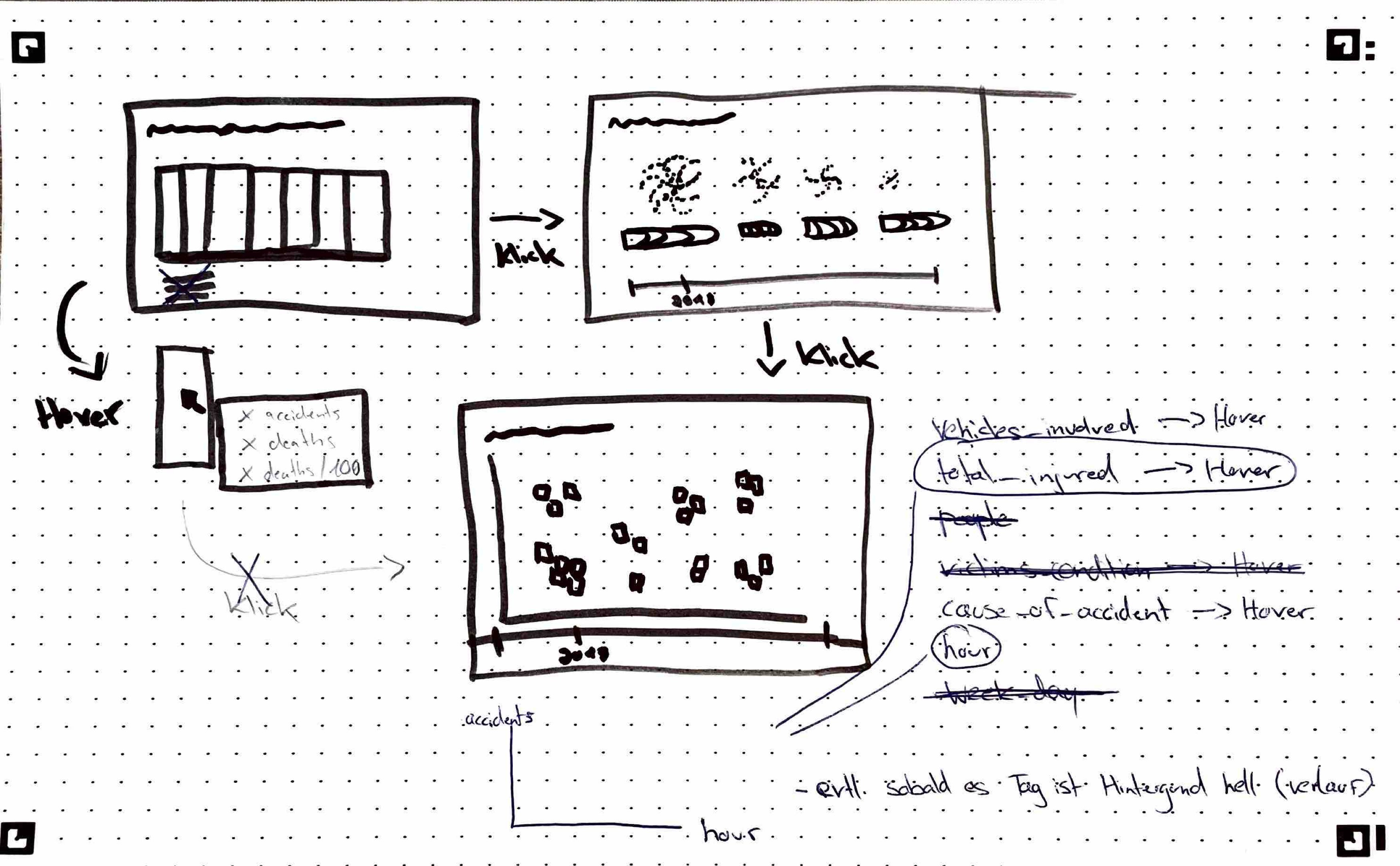
Mein Entwurf besteht aus drei Seiten, die unterschiedliche Detailstufen der Daten darstellen:
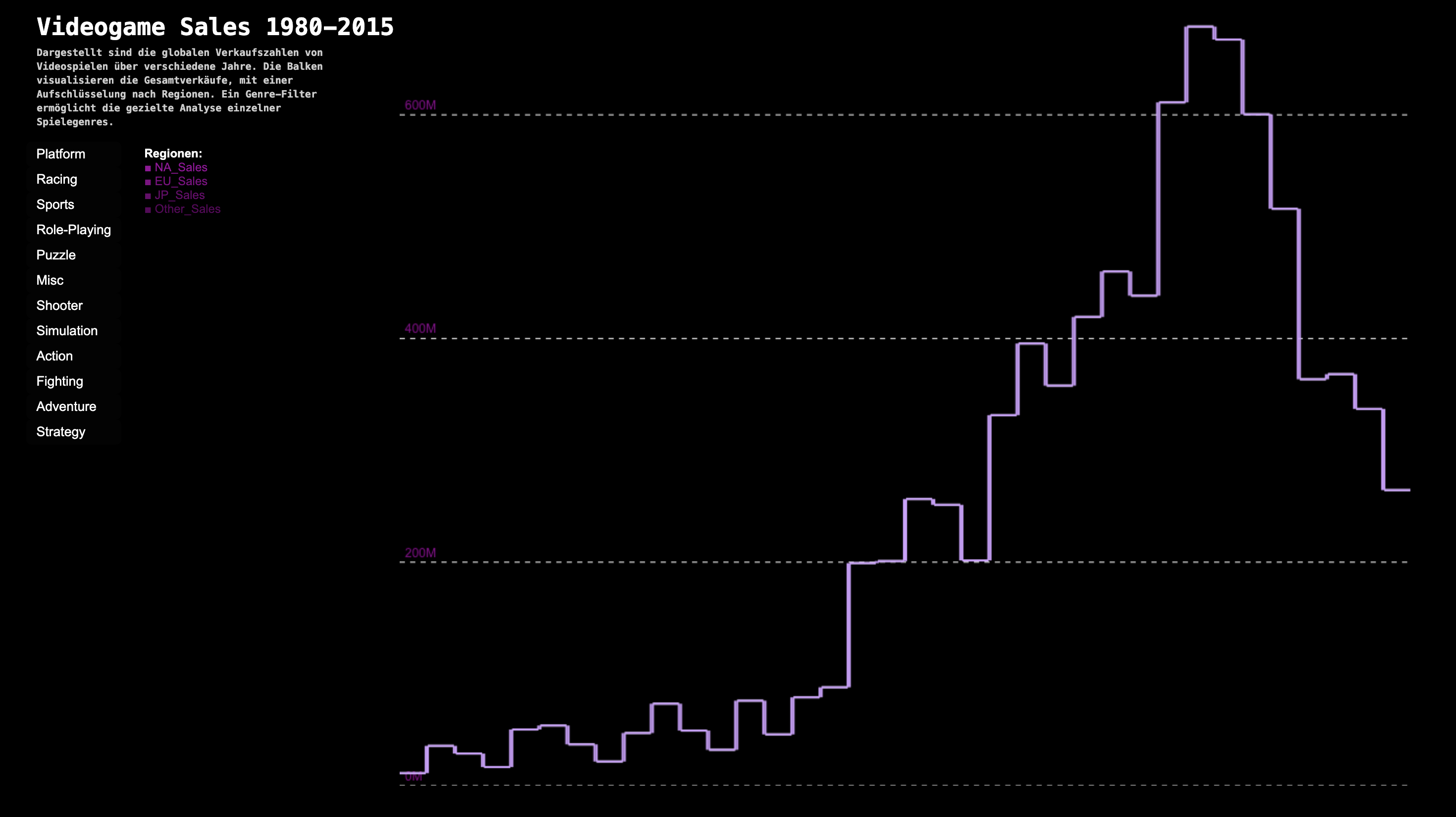
1. Startseite (Übersicht)
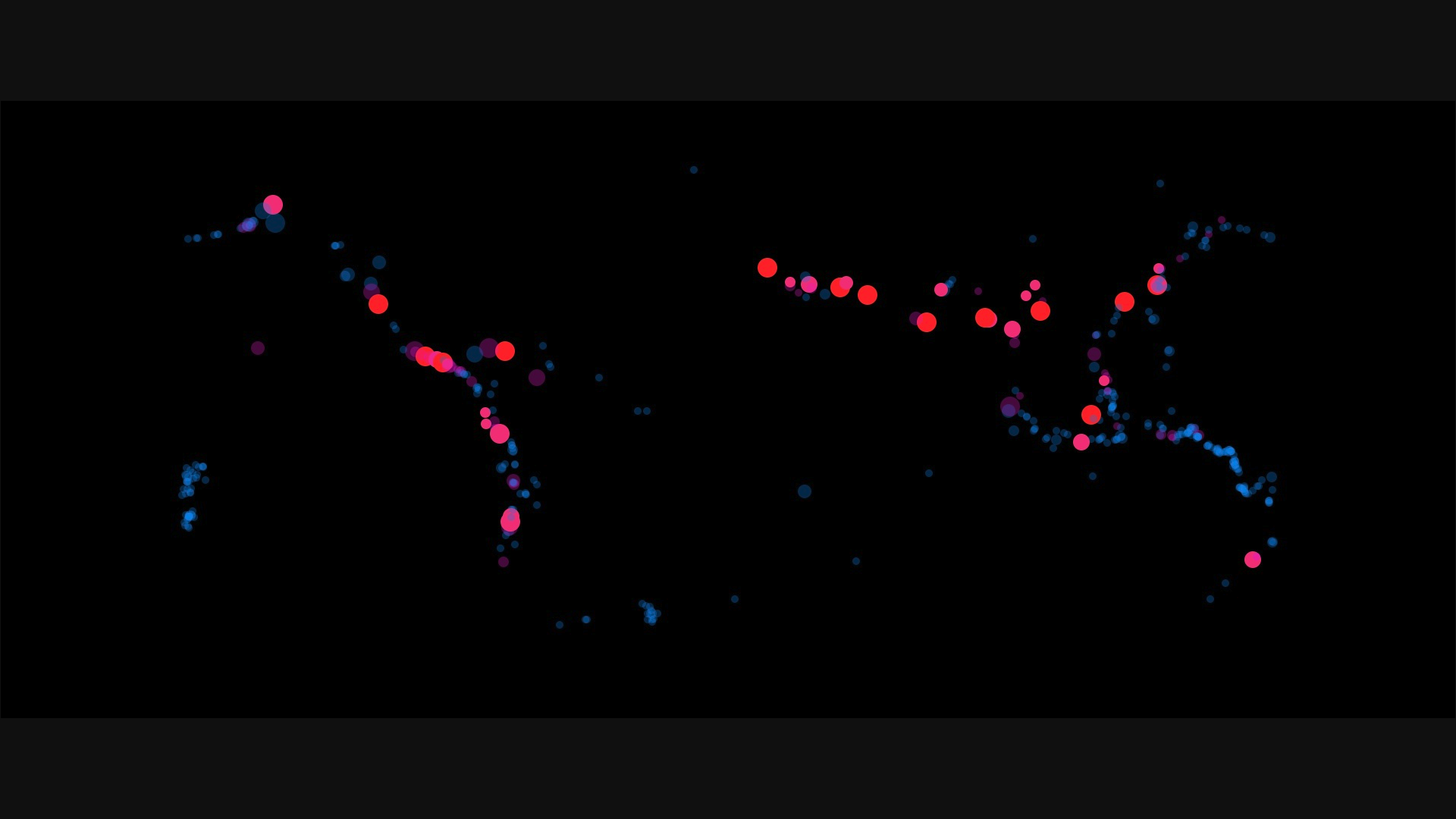
Auf der Startseite zeige ich eine erste visuelle Darstellung der Verkehrsunfälle in Brasilien. Sie wird in Balken dargestellt, deren breite auf der Anzahl der Unfälle pro Jahr basiert. Zudem erstreckt sich ein Farbverlauf über die Balken der die Tödlichkeit der Jahre zeigt. Durch einen Hover erhält man mehr Informationen.
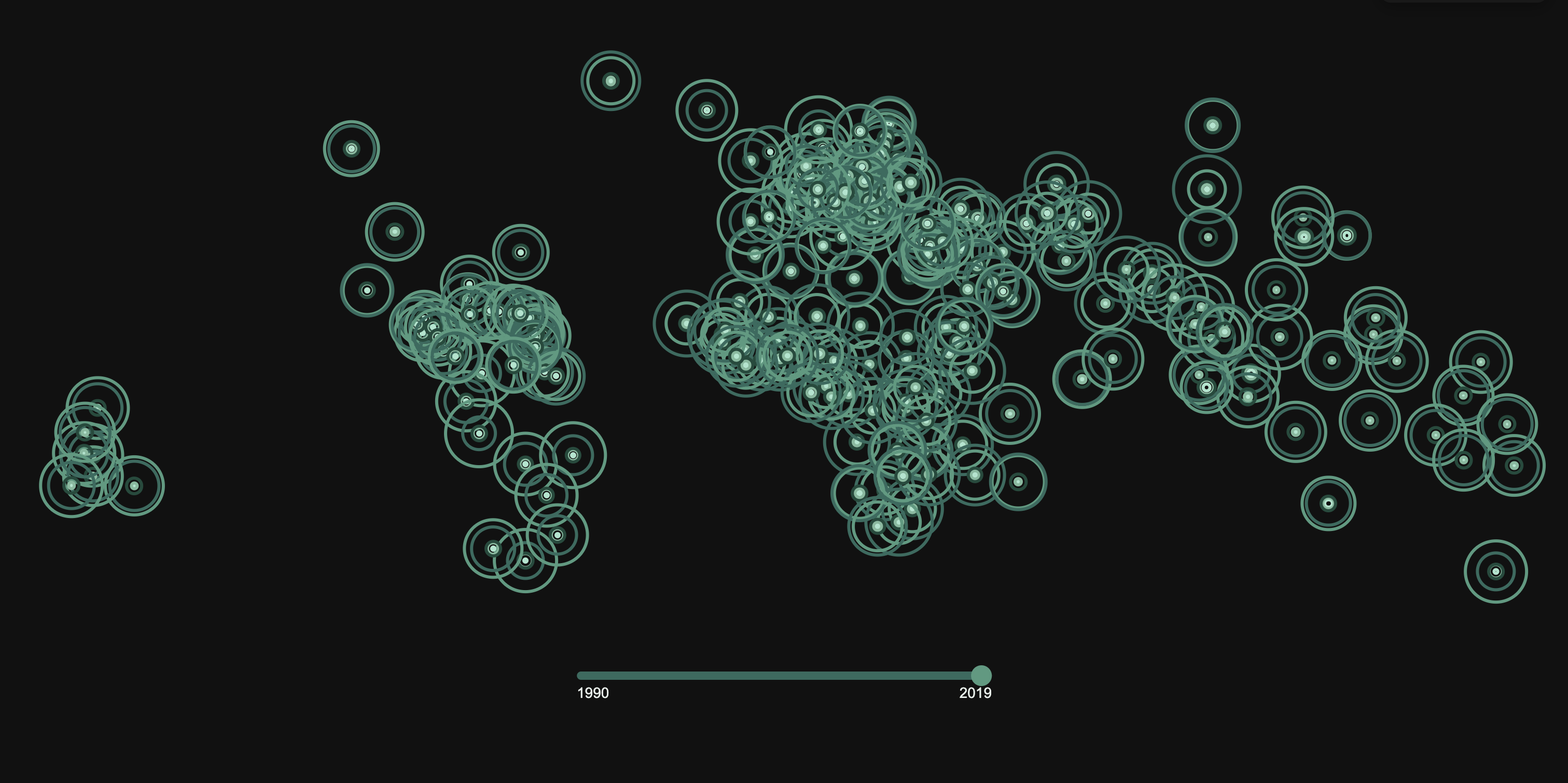
2. Klick auf einen der Balken
In dieser Ansicht gehe ich mehr ins Detail und stelle spezifische Informationen zu den Unfällen dar. Ich visualisiere die Verteilung nach Verletzungsschwere und durch Checkmarks kann man sich anzeigen lassen bei welcher Wetterbedingung die Unfälle passiert sind. Diese Seite soll es ermöglichen, tiefere Zusammenhänge zu erkennen.
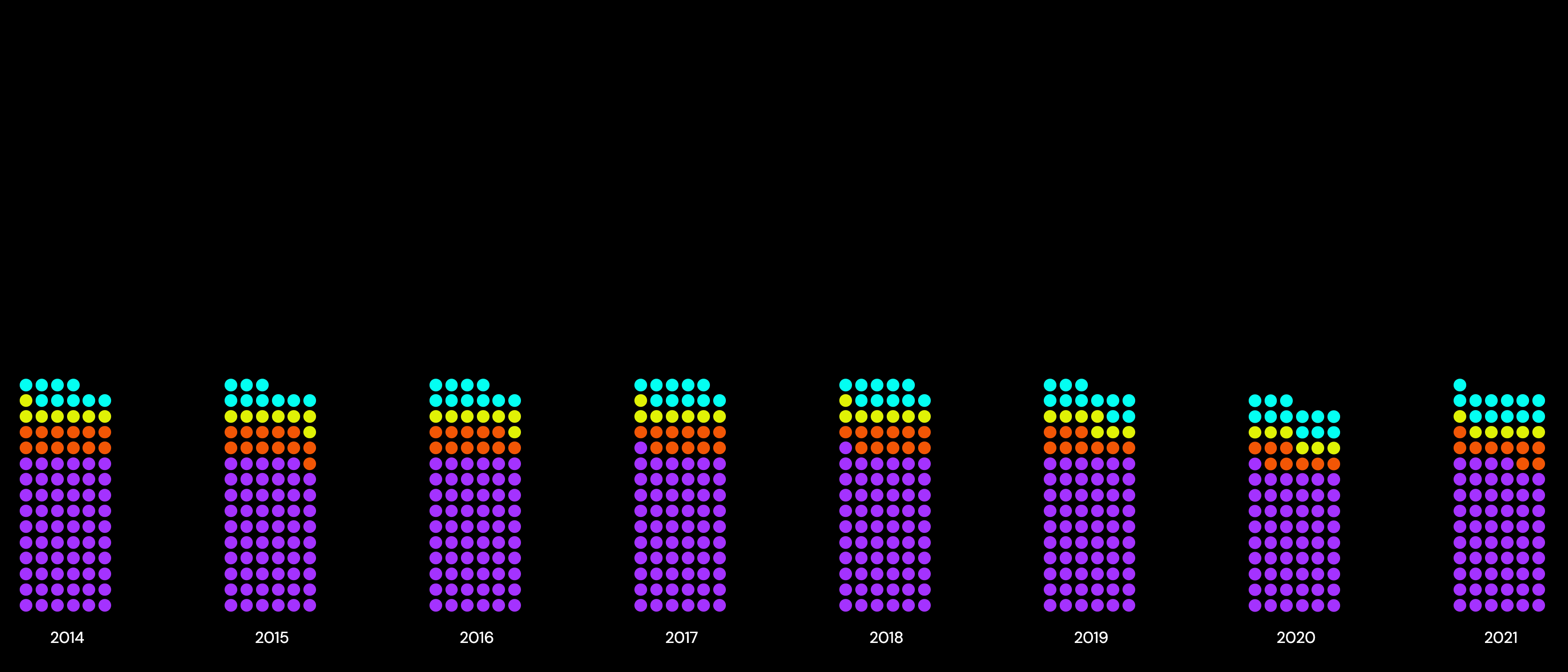
3. Detailansicht 2
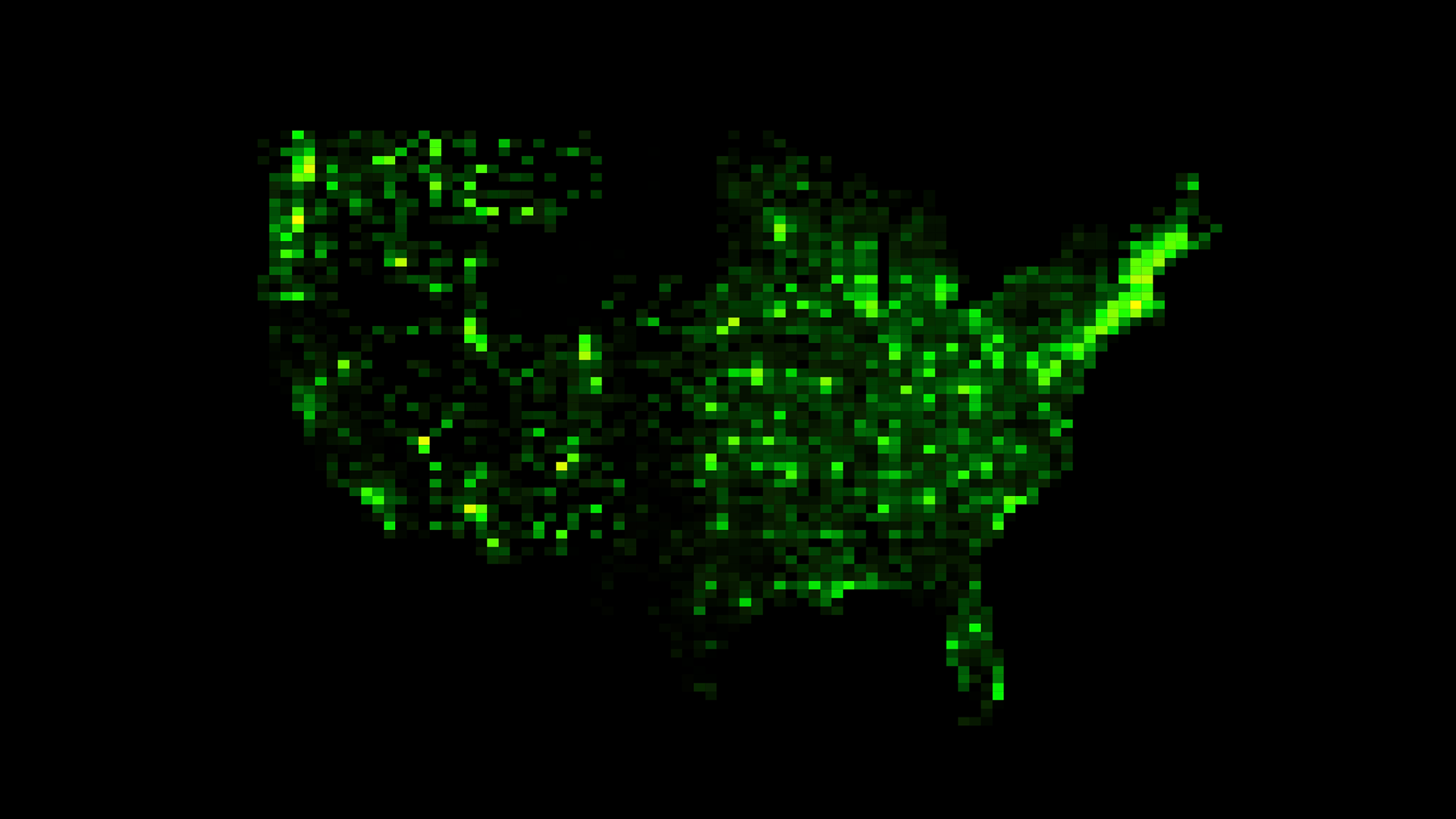
Ich habe eine Heatmap entwickelt, die die Verkehrsunfälle basierend auf Wochentag und Uhrzeit visualisiert. Damit kann ich auf einen Blick erkennen, zu welchen Zeiten besonders viele Unfälle passieren und welche Muster sich daraus ergeben.
Achsen & Struktur:
Die x-Achse stellt die Uhrzeit dar
Die y-Achse zeigt die Wochentage
Farbcodierung:
Dunklere oder intensivere Farben markieren Zeiten mit einer hohen Unfallrate.
Hellere Farben zeigen Zeiten mit weniger Unfällen.
Mit dieser Darstellung kann ich typische Muster erkennen, z. B. ob es mehr Unfälle während der Rushhour gibt oder ob bestimmte Tage besonders gefährlich sind.
Mein Ziel ist es, eine klare, gut verständliche Visualisierung zu schaffen, die sowohl eine schnelle Übersicht als auch detaillierte Einblicke in das Thema ermöglicht.
Prozess
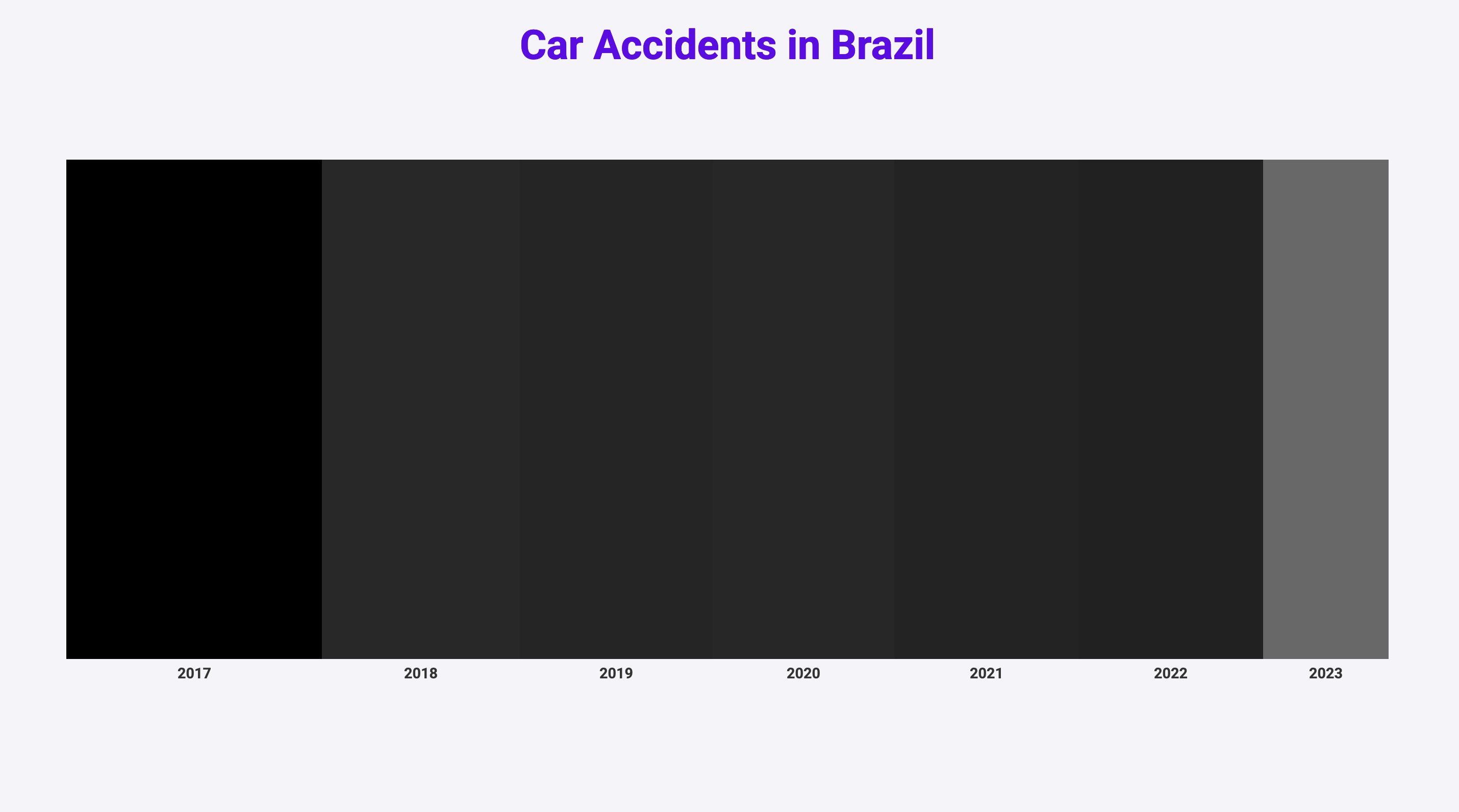
Zuerst habe ich eine grobe Struktur und Logik der 1. Seite programmiert.

Durch das Abrunden der Ecken ist die Breite der Balken leichter zu erkennen. Dies war nötig, da der Farbverlauf manchmal einen so geringen Unterschied von einem zum nächsten Jahr hatte, dass die Farben beim Betrachten ineinander verschwommen sind.
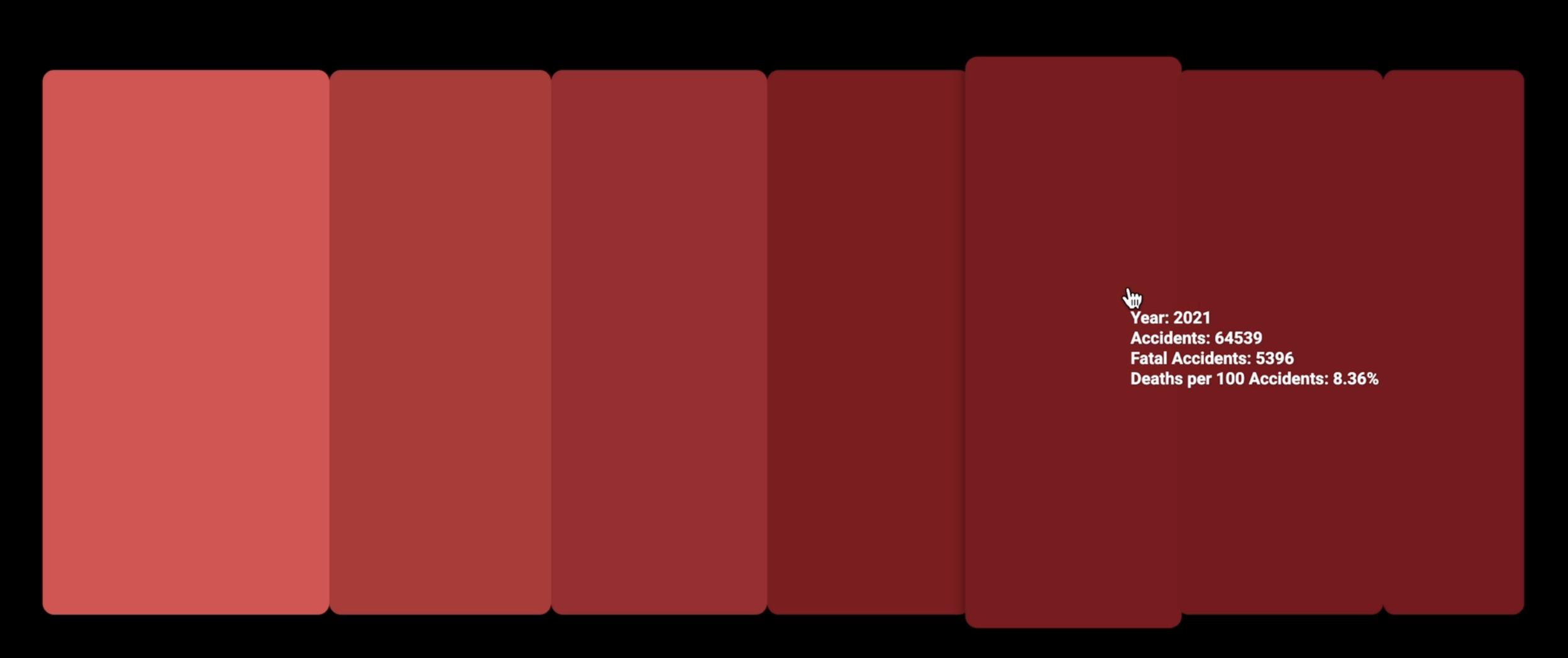
Mit dem Farbverlauf eines immer dunkler werdenden Rots ist es mir gelungen, die Aussage der Tödlichkeit verständlich darzustellen. Dabei habe ich den Quantitätskontrast genutzt, der besagt, dass eine zunehmend dunklere Farbe vom Betrachter als „mehr“ wahrgenommen wird.
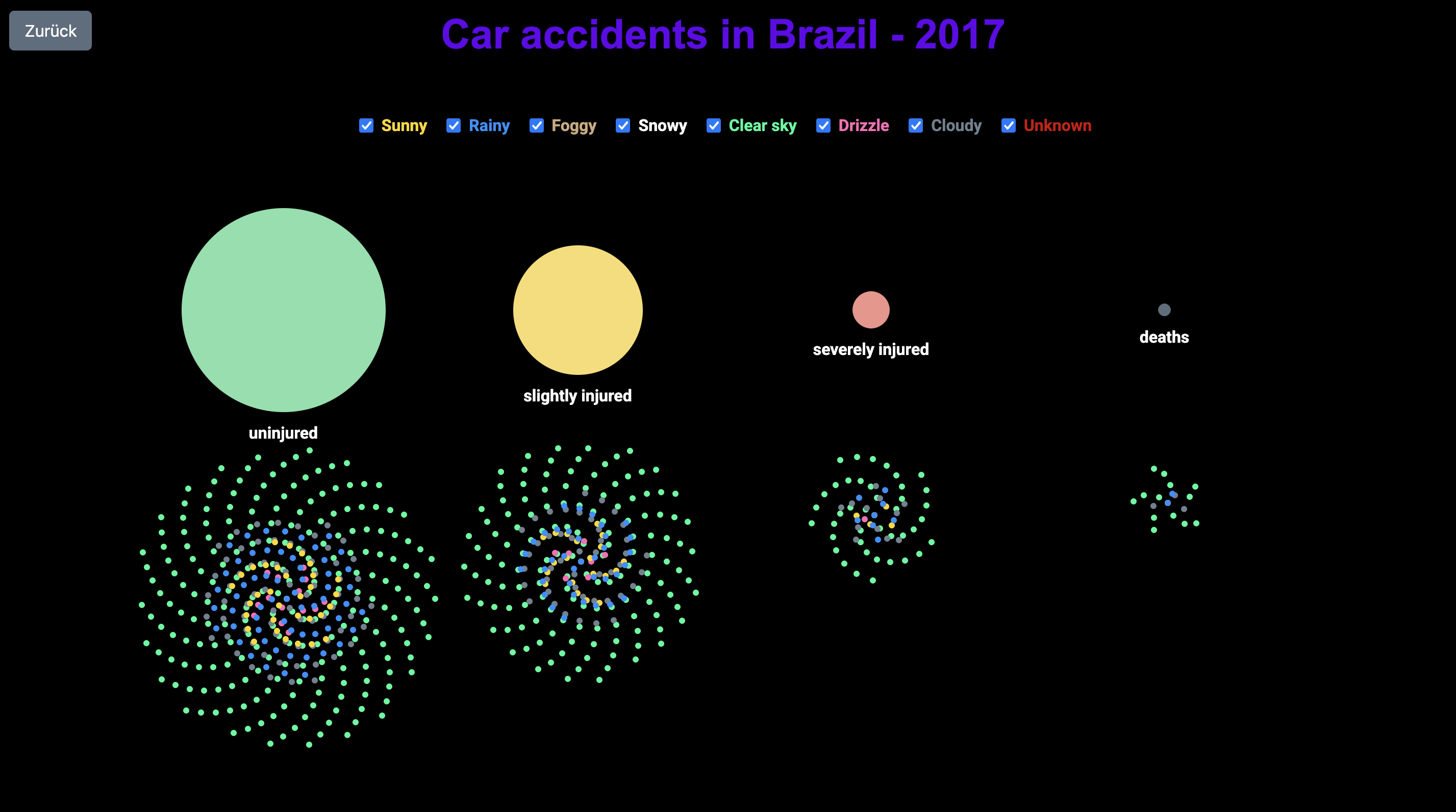
Das war der erste Plan zur Umsetzung von Seite 2. Es wurden die Verletzungsgrade und die Wetterbedingungen in zwei verschiedenen Formen dargestellt. Dennoch so, dass man sie aufeinander beziehen kann. Im weiteren Schritt wollte ich diese Ansicht noch optimieren.

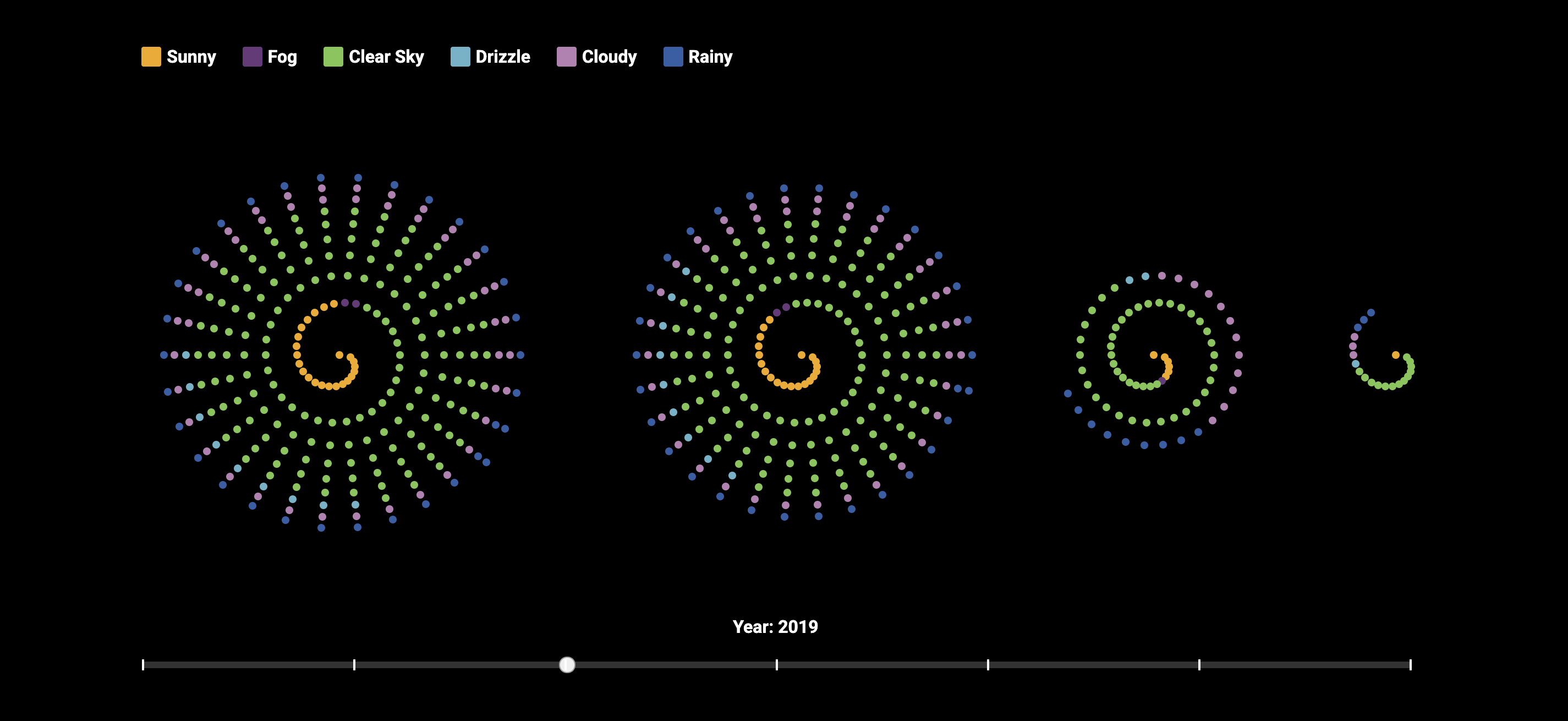
Ich entschied mich die bislang noch getrennt Dargestellten Daten in Spiralen zu kombinieren. So hat man einen noch besseren Bezug. Was man hier sieht ist die reine Darstellung der verschiedenen Verletzungsgrade. Pro 250 Unfälle mit entsprechender Condition steht ein Punkt. Ich habe diese Farben bewusst gewählt, um die Schwere der Verletzungen auf eine intuitive Weise darzustellen. Diese Farbpalette erzeugt eine natürliche Abstufung von harmlos bis lebensbedrohlich.
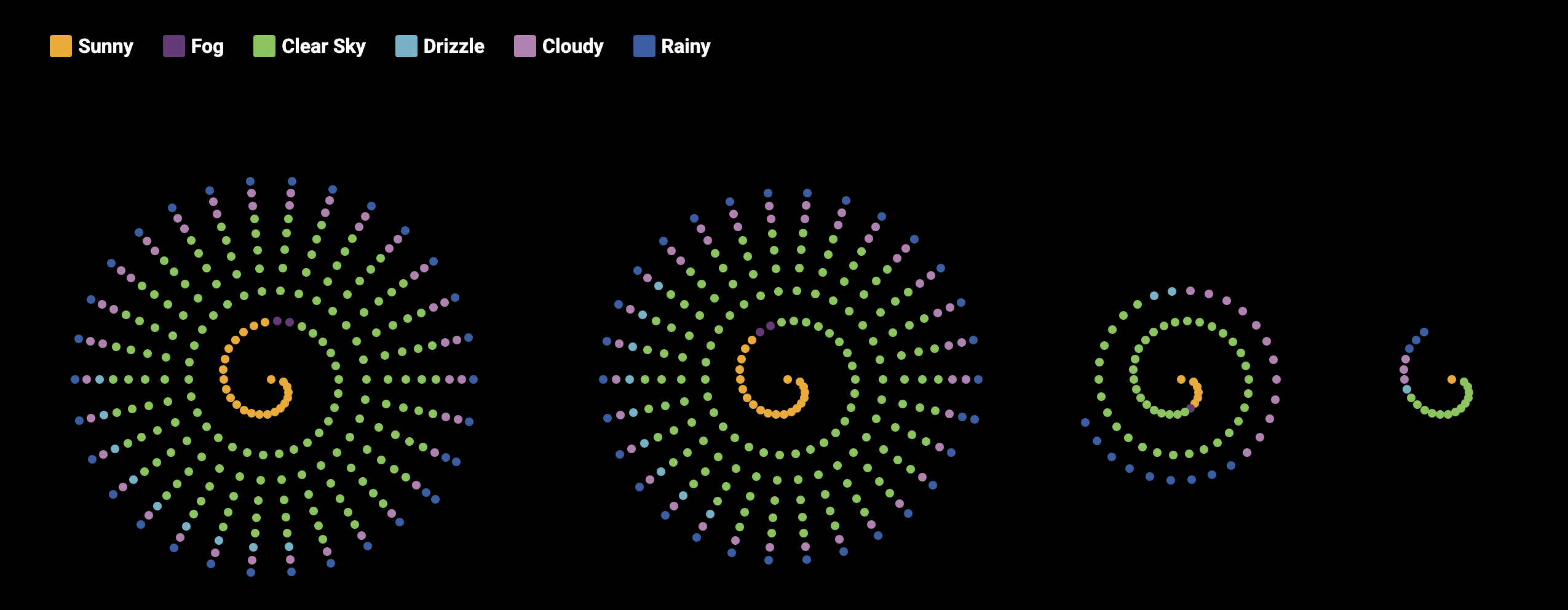
Durch die Checkmarks können direkt in den Spiralen die Wetterbedingungen angezeigt werden. Ich habe diese Farben bewusst gewählt, um die verschiedenen Wetterbedingungen möglichst intuitiv und emotional verständlich darzustellen. Diese Farben ermöglichen eine klare Unterscheidung der Wetterzustände, ohne dass es zu starken Überschneidungen kommt.

Problem: Farbbezug zur auf Seite 1 dargestellten Tödlichkeit

Problem: Weiß wirkt „leer“, was zu einer falschen Assoziation führt.
Endergebnis
(Ton an)