Bachelorarbeiten Interaktionsgestaltung
redato – ein onlinebasiertes Datenverwaltungstool für Wissenschaftler*innen

Beschreibung
Redato ist ein onlinebasiertes Datenverwaltungstool für Wissenschaftler. Mit dieser Applikation werden Forschungsdaten mit ihren entsprechenden Metadaten veröffentlicht und unter Achtung des Dateneigentums gesucht und mit anderen Nutzern des Tools geteilt. Im Gegensatz zum Status Quo ähnlicher Tools, mithilfe derer eine Publikation erst nach Abschluss des Forschungsprojektes erfolgt, bietet redato die Möglichkeit, an jedem Punkt des Forschungsprozesses die Daten zu veröffentlichen. Neu dabei ist, dass in redato der jeweilige Prozessschritt des Forschungsprozesses in den Metadaten gekennzeichnet wird. Dabei gilt: je besser und umfangreicher die Anwender die Metadaten pflegen, desto höher ist die Wahrscheinlichkeit, dass andere die Daten finden. Werden die Daten gefunden und es besteht Interesse an den Daten, kann der Finder den Dateneigentümer über eine Direktnachricht um Datenfreigabe bitten.
Redato schafft also die Grundlage für Datenaktualität (durch Synchronisation mit dem Serverlaufwerk des Wissenschaftlers), der Kommunikation (durch das Anfragen der Daten per Direktnachricht), der hohen Datenexzellenz (je besser die Metadaten sind, desto leichter werden die Forschungsdaten gefunden) und der Nachnutzung sowie der damit einhergehenden Reputation (leicht gefundene Daten können leichter nachgenutzt werden).
Funktionsweise
Beim Abschluss des Projektes redato, wurden zwei Hauptfunktionen prototypisch umgesetzt. Dies ist die Projektübersicht und die Datensuche. Weitere Funktionen, wie zum Beispiel ein Kommunikationsmodul, wurden angedacht, sind aber nicht Teil dieser Dokumentation.
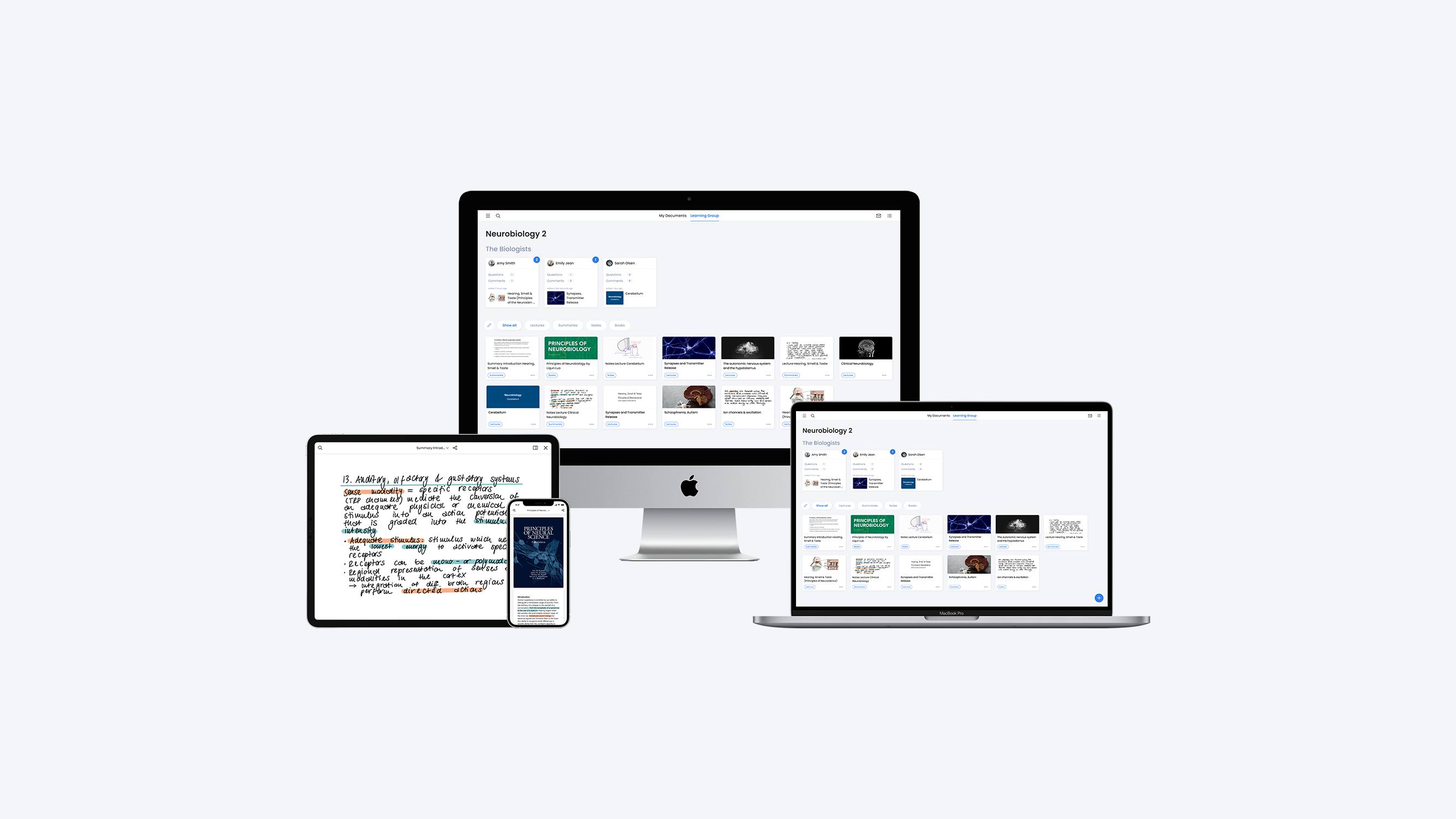
1. Projekte
Projektauswahl und Projektmetadatenübersicht
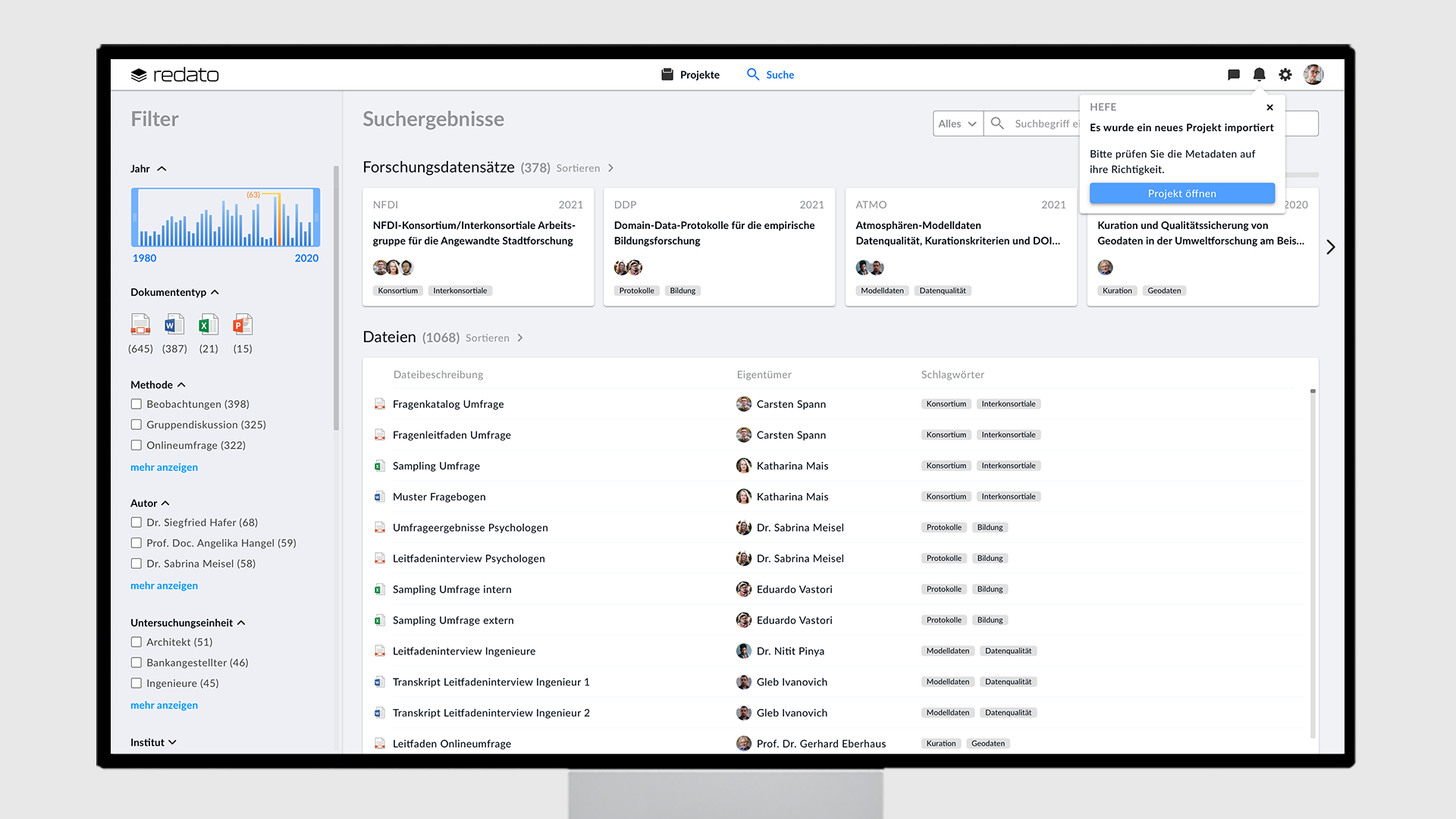
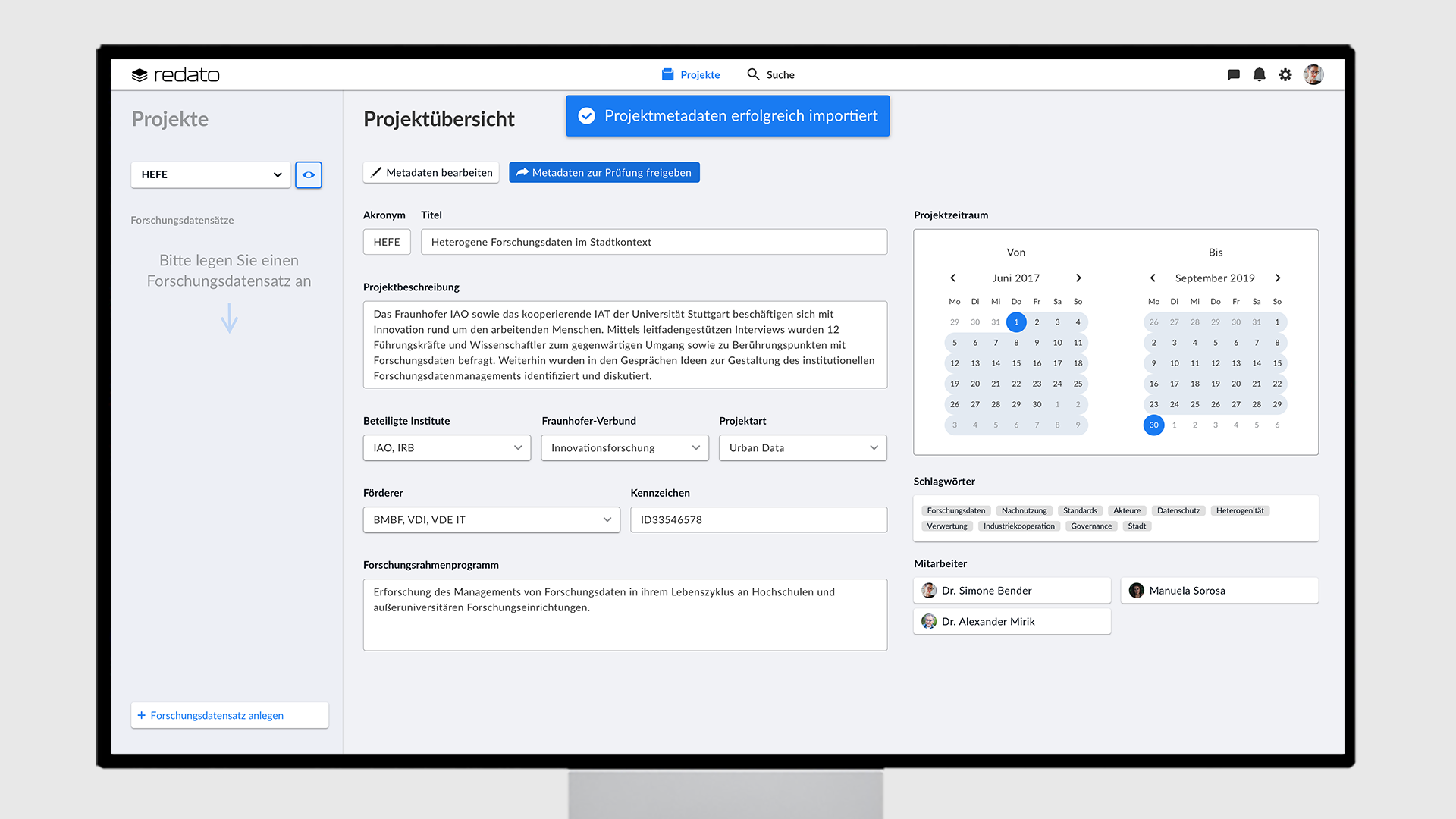
Ist der Zuwendungsbescheid für das Projekt eingetroffen, erhält der Nutzer eine Mail mit dem Inhalt, dass redato die Projektmetadaten importiert hat. Öffnet der Nutzer nun redato, bekommt der Nutzer eine entsprechende Mitteilung, die ihn über den Metadatenimport informiert. Navigiert der Nutzer auf die Mitteilung, gelangt er zu der Projektmetadatenübersicht. Öffnet der Nutzer das Projekt, kann er die importierten Projektmetadaten prüfen und die Richtigkeit der Daten dem Datenkurator gegenüber bestätigen – oder bei Bedarf, die Daten ändern. Zwischen den Projekten kann der Nutzer über das Dropdown-Menü wechseln. Die Anlage eines Projektes ist die Voraussetzung dafür, dass ein Forschungsdatensatz angelegt und anschließend Dateien synchronisiert werden können.
Forschungsdatensatz anlegen
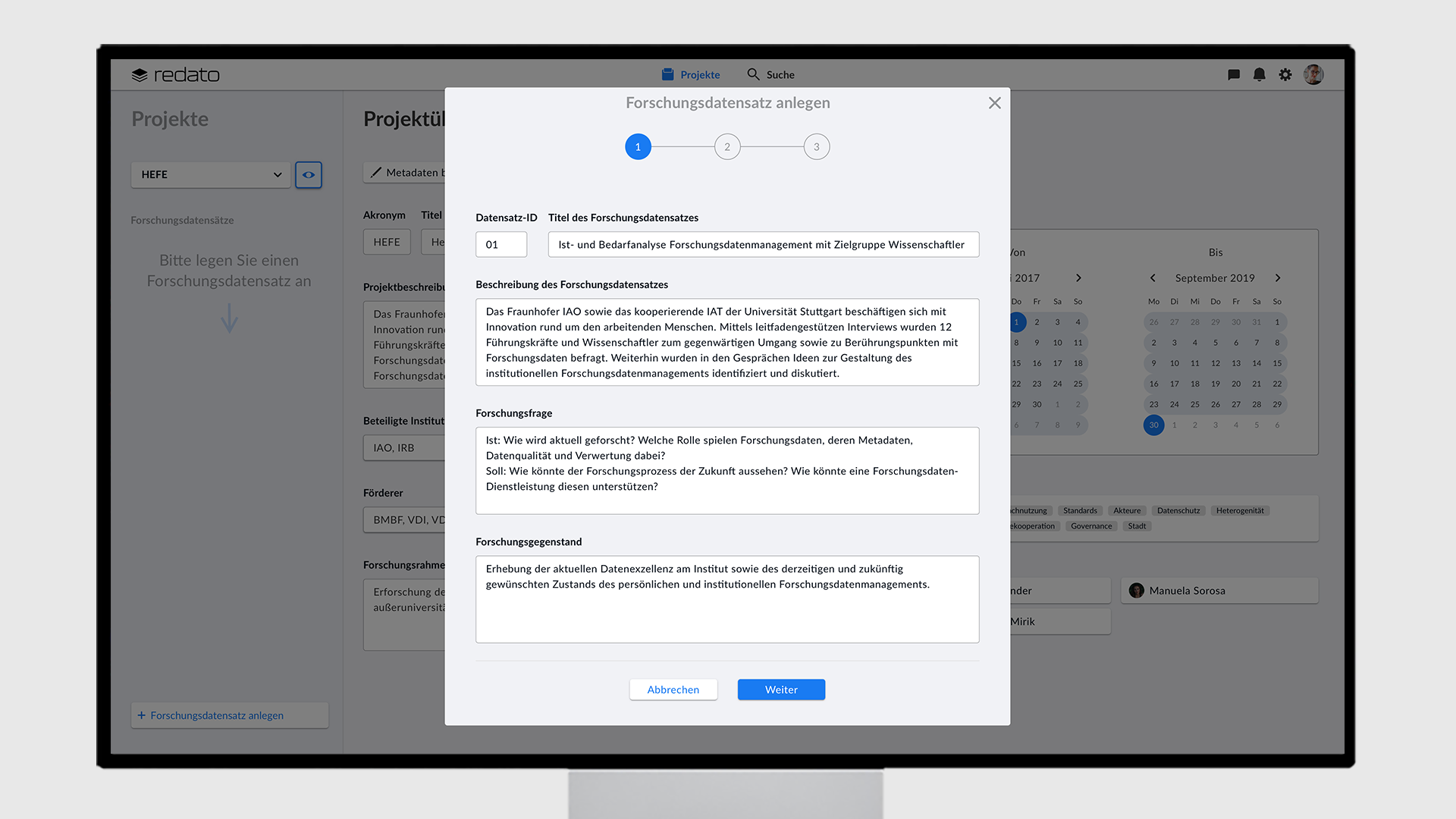
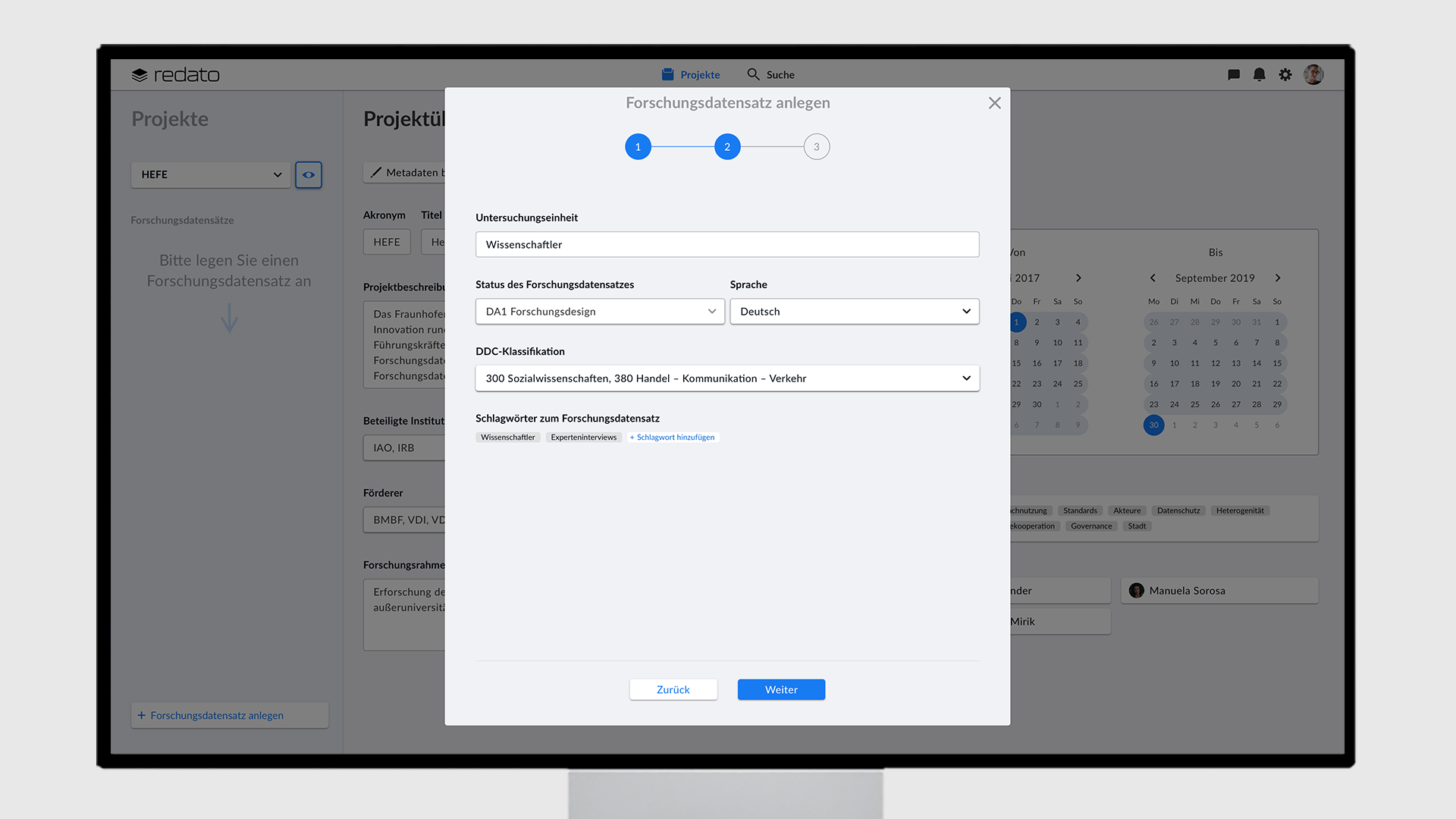
Sobald die Projektmetadaten überprüft und freigegeben wurden, kann der Nutzer die Forschungsdatensätze anlegen. Über ein Overlay wird er in drei Schritten durch den Erstellprozess geleitet.
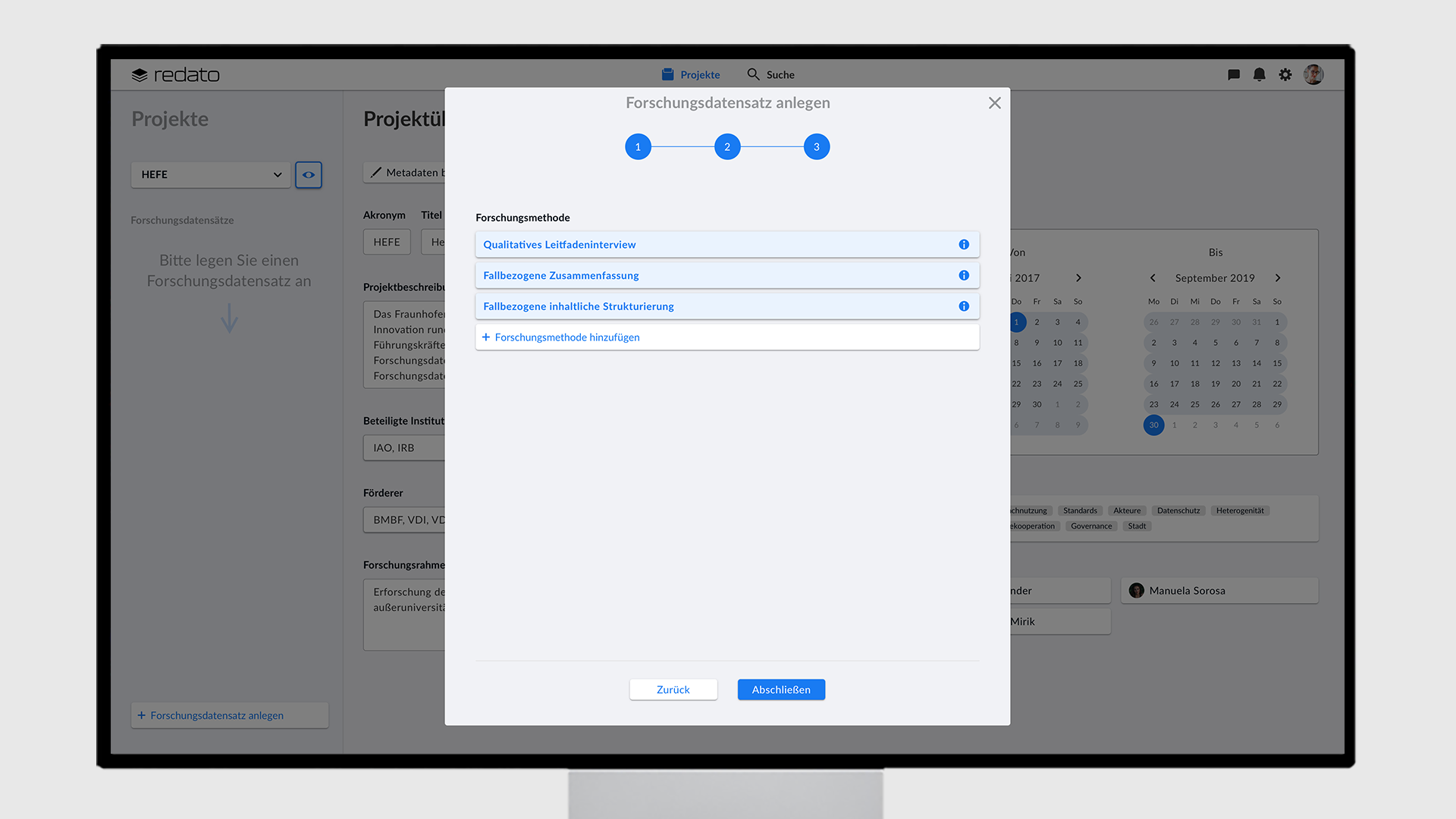
In den ersten beiden Schritten können Metadaten wie der Titel, die Beschreibung und die Untersuchungseinheit eingegeben werden. Im dritten Schritt kann der Nutzer eine oder mehrere bereits existierende Forschungsmethode(n) auswählen oder eine neue Methode erstellen. Sollte der Nutzer noch nicht alle Textfelder ausfüllen können, kann er dies zu jeder Zeit über den Viewport unter “Metadaten” nachholen. Wenn der Nutzer einen Forschungsdatensatz angelegt hat, so erscheint dieser unter dem Dropdown-Menü des Projektes als Navigationselement.
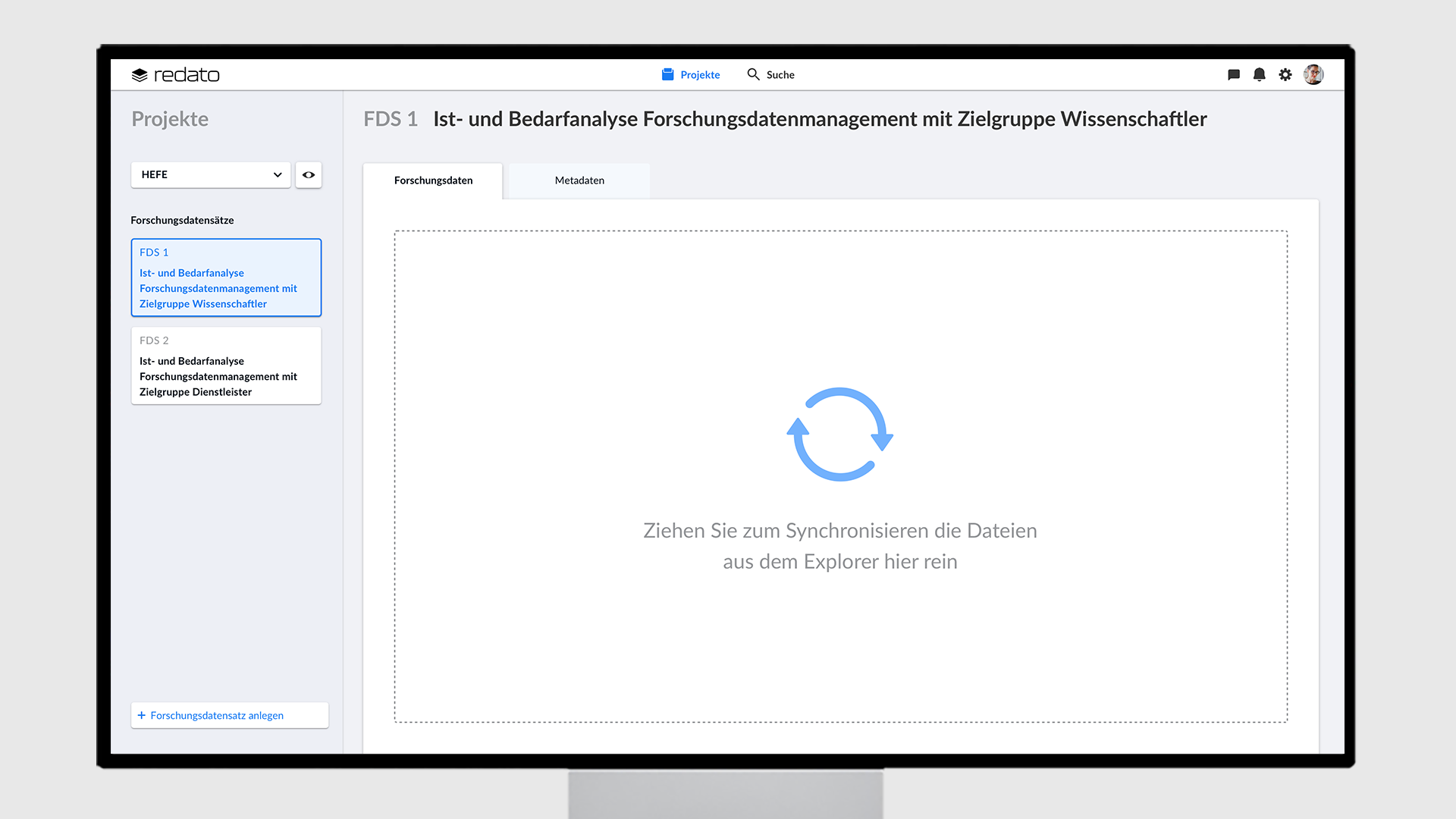
Dateien synchronisieren
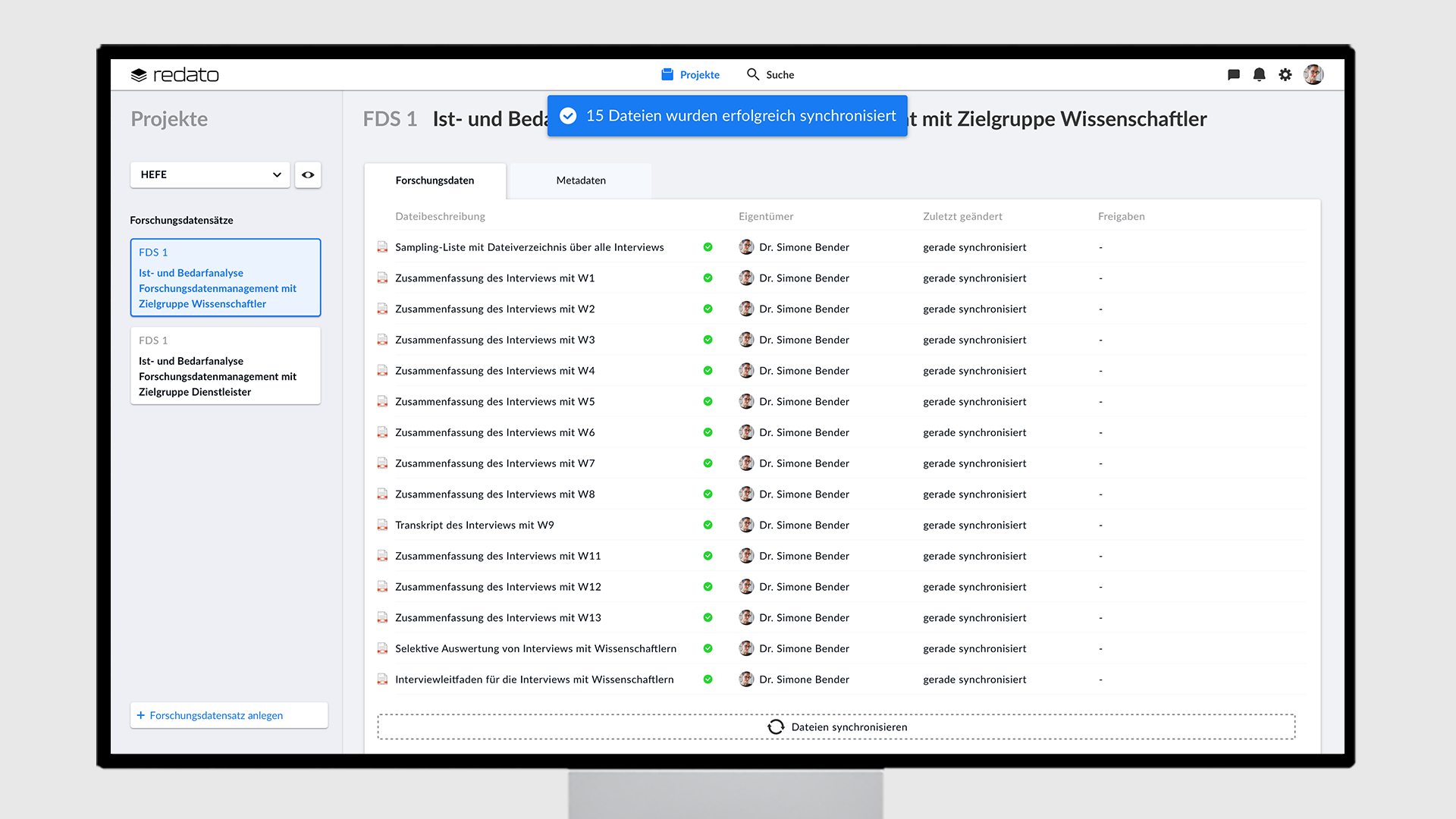
Erst wenn der Nutzer einen Forschungsdatensatz angelegt hat, kann er Dateien von seinem persönlichen Serverlaufwerk mit redato synchronisieren. Damit wird die Voraussetzung geschaffen, dass die geteilten Dateien mit Metadaten beschrieben sind. Über die Qualität der Metadaten könnte eine interne Abteilung, die zum Beispiel aus Datenkuratoren und beratenden Wissenschaftlern besteht, wachen. Die Synchronisation erfolgt über „drag and drop“ oder durch Klicken auf die Fläche “synchronisieren”. Die Statusanzeige jeder Datei zeigt dem Nutzer an, ob die Datei erfolgreich hochgeladen, der Synchronisationsvorgang noch anhält, oder eine neue Version der Datei vorhanden ist. Da es mehrere Mitarbeiter pro Forschungsdatensatz geben kann, zeigt das System dem Nutzer den Dateneigentümer der Datei an und wem eine Datei freigegeben wurde.
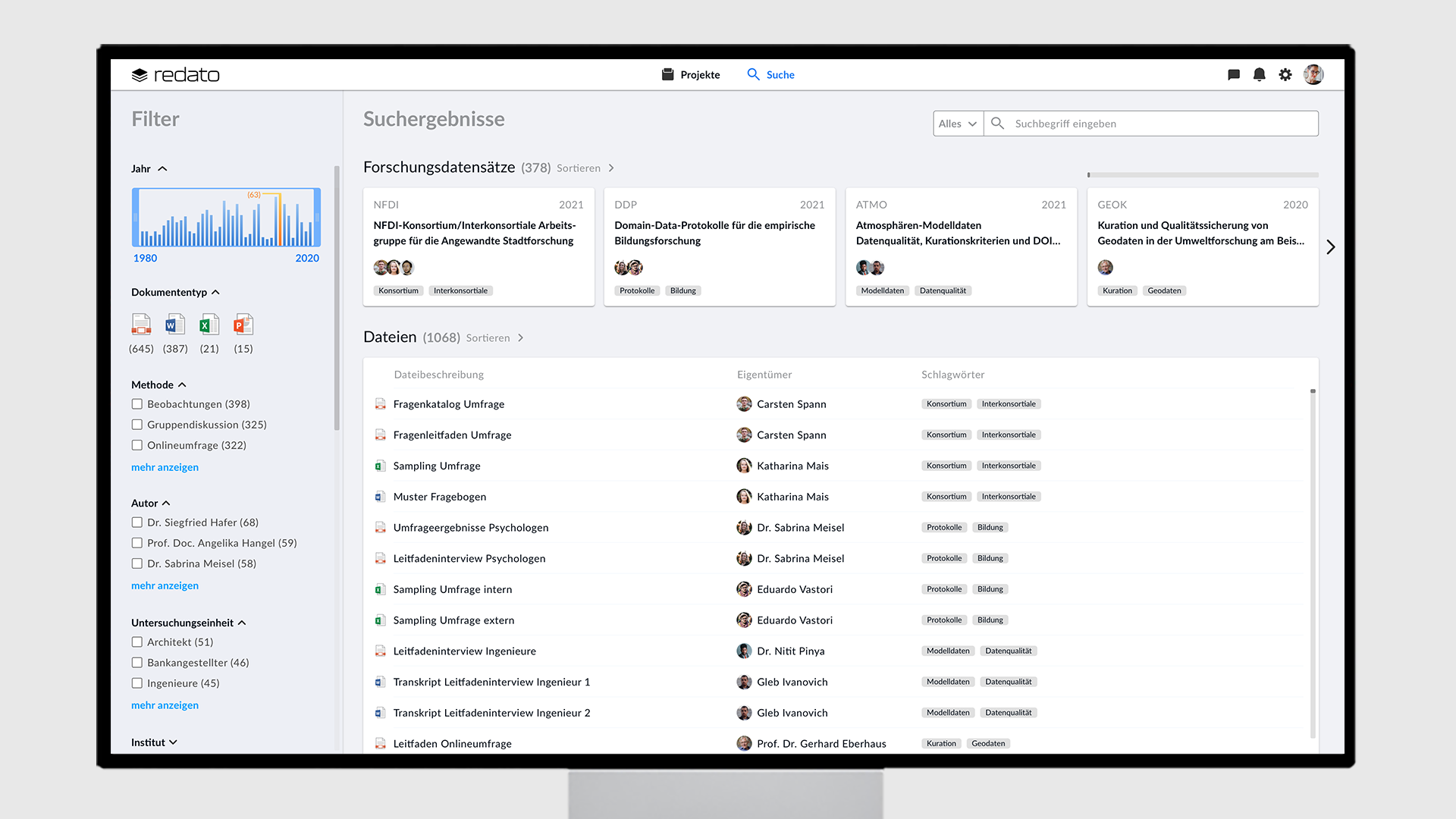
2. Suche
Sucheingabefeld und Suchfilter
Befindet sich der Nutzer in dem Reiter „Suche“, so hat er die Möglichkeit, einen Suchbegriff in das Eingabefeld einzugeben und weitere Suchfilter hinzuzufügen. Alternativ bietet das System die Möglichkeit, direkt ohne eine Eingabe in das Suchfeld einen Suchfilter auszuwählen.
Forschungsdatensatz und Dateien
Grundsätzlich werden immer vier Forschungsdatensätze und zwölf Dateien angezeigt. Durch die Forschungsdatensätze kann der Nutzer in horizontaler Ebene und durch die Dateien kann er in vertikaler Ebene navigieren. Visualisiert sind die Forschungsdatensätze als Karten. Sie enthalten das Projektakronym für die eindeutige Zuordnung (mehrere Forschungsdatensätze können dasselbe Projektakronym haben), das Erstellungsjahr, den Titel des Forschungsdatensatzes, die Projektbeteiligten und die Schlagwörter.
Die Dateien sind in einer Listenansicht dargestellt und mit einer Dateibeschreibung versehen. Zusätzlich werden sowohl der Dateieigentümer und zum anderen die Schlagwörter des Forschungsdatensatzes, dem die Datei zugeordnet ist, angezeigt.
Im „default-Zustand“ werden alle angelegten Forschungsdatensätze und alle synchronisierten Dateien innerhalb des Instituts nach dem Erstellungsjahr absteigend angezeigt. Die Dateien werden entsprechend der Forschungsdatensätze sortiert, beziehungsweise werden alle Dateien die im neuesten Forschungsdatensatz vorhanden sind, angezeigt. Darunter liegen die Dateien vom zweitneuesten Forschungsdatensatz, und so weiter. Als Erkennungsmerkmal dienen der Dateneigentümer und die Schlagwörter. Sobald ein Suchbegriff eingegeben oder ein Suchfilter ausgewählt ist, werden die Forschungsdatensätze und die Dateien an die Kriterien angepasst. Auch hier werden die Forschungsdatensätze nach dem Erstellungsjahr absteigend und die Dateien innerhalb der Forschungsdatensätze angezeigt.
Freigabe anfordern
Wählt der Nutzer im Anschluss an seine Datensuche einen Forschungsdatensatz oder eine Datei aus, so bekommt er mehr Informationen auf der rechten Seite der Benutzeroberfläche angezeigt. Hier hat er die Möglichkeit, die Datei anzufordern. Der Nutzer fragt den Dateneigentümer an und der Dateneigentümer
muss diese Anfrage bestätigen, sodass er weiß, wer seine Dateien verwendet hat.
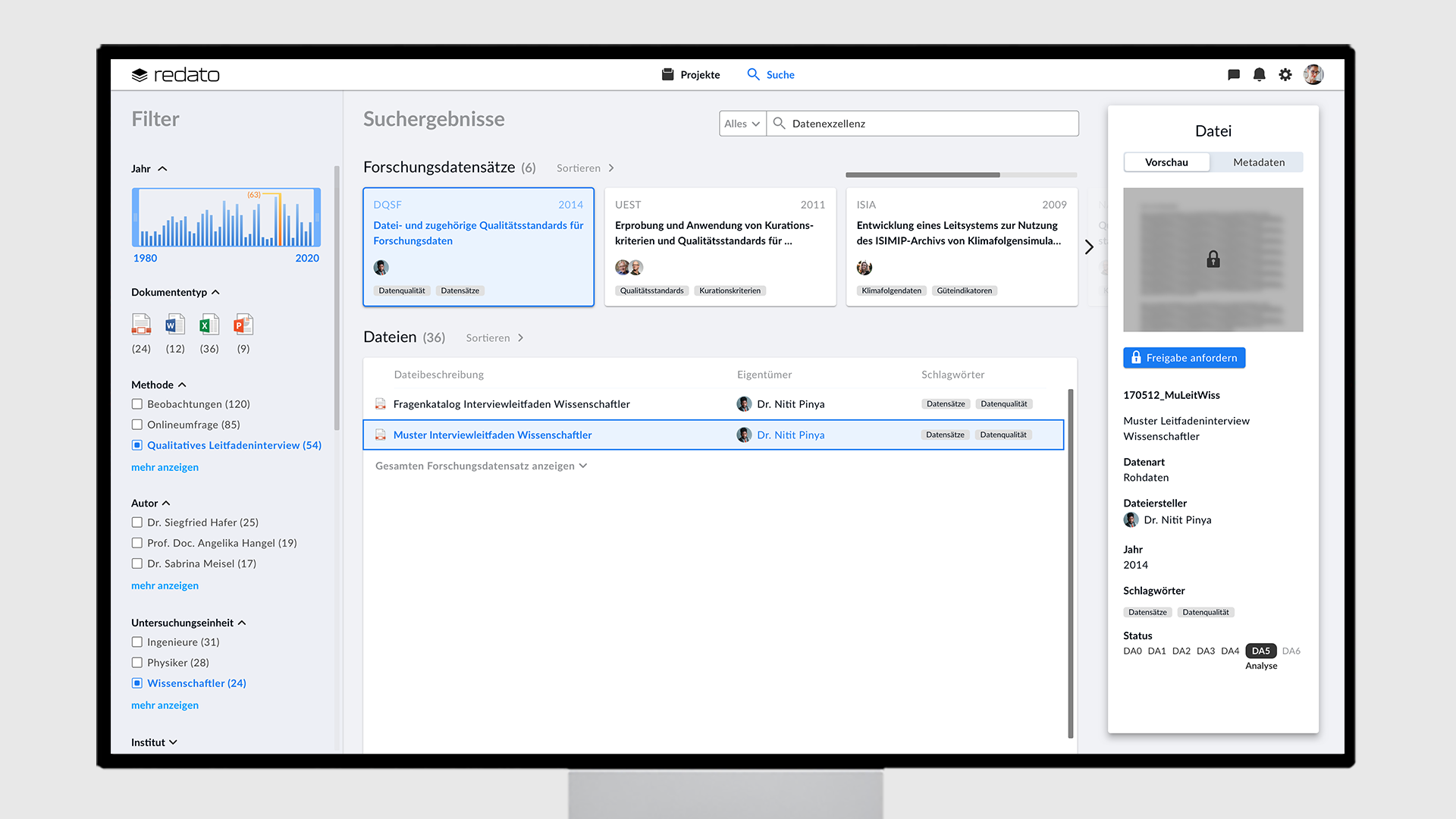
(image: suche_freigabe-anfordern.png caption: Der Nutzer hat den Button “Freigabe anfordern” (siehe oberen Screen” geklickt. Nun kann er die Datei anfordern und zusätzlich einen Nachrichtentext an den Empfänger verfassen.)
Cedric Döz, Florian Nagel, Oliver Rieger
BetreuungProf. Carmen Hartmann-Menzel, Florian Geiselhart
Tags